Last Monday at 11pm, a garage-door article drafted itself. An AI named Rick cut forty words from it. An AI named Margaret fact-checked what remained — and refused to let it publish.
The article went back. Claims were sourced. Margaret passed it the second time. An AI named Steve read the whole thing and rendered a single-word verdict: SHIP.
Total cost, across both runs: thirty-five cents.
Before we get to the money, I want to talk about Margaret. Because the pipeline isn't interesting because it's cheap. It's interesting because it has someone in it who is willing to say no.
Who these people are
Margaret Stone is the Safety and Systems editor at garagedoorscience.com. She has a portrait on the About page, a bio, and a byline on every article she touches. She covers how-it-works deep-dives, technical explainers, and anything that brushes against safety — how to test garage-door balance, when to call a pro, what not to touch yourself.
She is also a language model. Her persona was written by a different language model, anchored to Margaret Hamilton's voice — methodical, precise, the kind of person who checks her work twice because she was on the team that made sure Apollo 11 didn't crash into the moon. The name isn't accidental.
Rick Callahan edits for economy. His job is to cut. His persona is anchored to Rick Rubin's: strip to essence, remove everything that isn't the song. On the first article — 1,300 words about how to check garage-door balance — Rick took out 24 words. That's a light pass for him. But he ran it, and the cuts were real.
Then Margaret read it.
She flagged three claims. Not vague concerns — specific, named assertions in the draft that weren't sourced anywhere. Each one was the kind of thing that sounds true enough to publish and is wrong enough to matter: a specification presented as industry-standard, a safety margin stated as absolute, a maintenance interval given with a precision the draft had no basis to assert.
The article went to _pending_review/. It did not publish.
What Margaret catching those claims actually means
Here's the thing about unsourced claims: they aren't always false. The three Margaret flagged were probably fine. Probably close to accurate. A human editor in a hurry might have read past them, especially on a topic as unsexy as garage-door spring tension. They sound right. The reader would never know.
That's exactly the problem.
A content pipeline that publishes things that sound right isn't a content pipeline. It's a content mill. The only difference between a trustworthy pipeline and a mill is whether any gate in the chain is willing to kill the work.
Margaret is willing. She's not advisory. She doesn't say "you might want to check this." She routes the article to a folder that doesn't auto-merge. The article stops. Full stop.
I went and sourced the claims. Real sources — manufacturer documentation, industry maintenance guides. Then I ran the pipeline again. Margaret passed it. Steve read the final draft and issued his verdict. The article published.
That sequence matters. Not because any individual step is remarkable, but because every step had the authority to end the run. Most pipelines aren't built that way. Most pipelines have gates that say "flag for review" and ship anyway.
Steve's job, and why nuance is the wrong tool for it
Steve's role is the final gate. He reads the post-fact-check, post-URL-validation draft with a single question: is this worth publishing on garagedoorscience.com?
His answer is binary. SHIP or REJECT. No rubric, no score out of ten, no "publish with the following caveats." One word.
That sounds blunt. It is blunt. That's why it works.
A gate that can hedge is a gate that will hedge. Give a model a five-point quality scale and it will give you 3.7s and tell you to "consider strengthening section two." A 3.7 is advisory. A 3.7 means the article ships and you tell yourself you'll fix it later. You won't fix it later. Later is when the next Monday night cron runs.
Steve's binary forces the question earlier in the chain. If you know the final gate is SHIP or REJECT with nothing in between, you write better prompts for every stage before it. You don't let Rick be soft. You don't let Margaret be vague. The unforgiving verdict at the end makes every upstream step more honest.
What "human-in-the-loop" actually means
The human in this loop is me. But I was not present on Monday at 11pm. I was asleep. I didn't review the draft, I didn't approve the fact-check, I didn't pull the trigger on publishing. The pipeline ran. The pipeline decided.
So what is the human for?
I wrote the prompts. I designed what Margaret checks for, how Rick is allowed to cut, what Steve is permitted to pass. I set the threshold at which the pipeline routes to human review instead of auto-merging. I wrote the deny-list — nine patterns that will stop any article cold and send it to me, no gate needed: anything that touches springs, cables, DIY electrical, overhead track removal. The human job is writing the fence, not standing at the gate.
That framing makes some people uncomfortable. I understand it. The instinct is that consequential decisions should have a human watching them happen in real time. But "watching it happen" is not the same as "having designed the system that makes it happen correctly." I'm not in the loop on every article. I am in the loop on what Margaret is allowed to flag, how Rick is allowed to cut, and what Steve is allowed to bless. Those are the decisions that matter. The rest is execution.
What happens when you soften any gate
Imagine Margaret becomes advisory. She still reads every draft. She still notices the unsourced claims. But instead of routing to _pending_review/, she appends a note: "consider verifying claim three."
The note goes into the draft. Steve reads the draft, sees the note, reads the claim, and decides it's probably fine. Steve passes it. The article publishes.
Now you have a published article with an unsourced claim and a note in the revision history that someone once said to check it. That is not a content pipeline. That is a content mill with paperwork.
The moment any gate becomes advisory-only, the whole architecture softens. Not because any one article is a disaster — it probably isn't — but because the system learns that gates are suggestions. The next time Rick is uncertain about a cut, he leaves it in. The next time Margaret notices something borderline, she flags it lightly and moves on. And Steve, reading drafts that have been handled by gates that don't actually stop anything, starts passing more.
Binary gates are not strict because strictness is a virtue. They're strict because strictness is the only way gates work.
The thirty-five cents
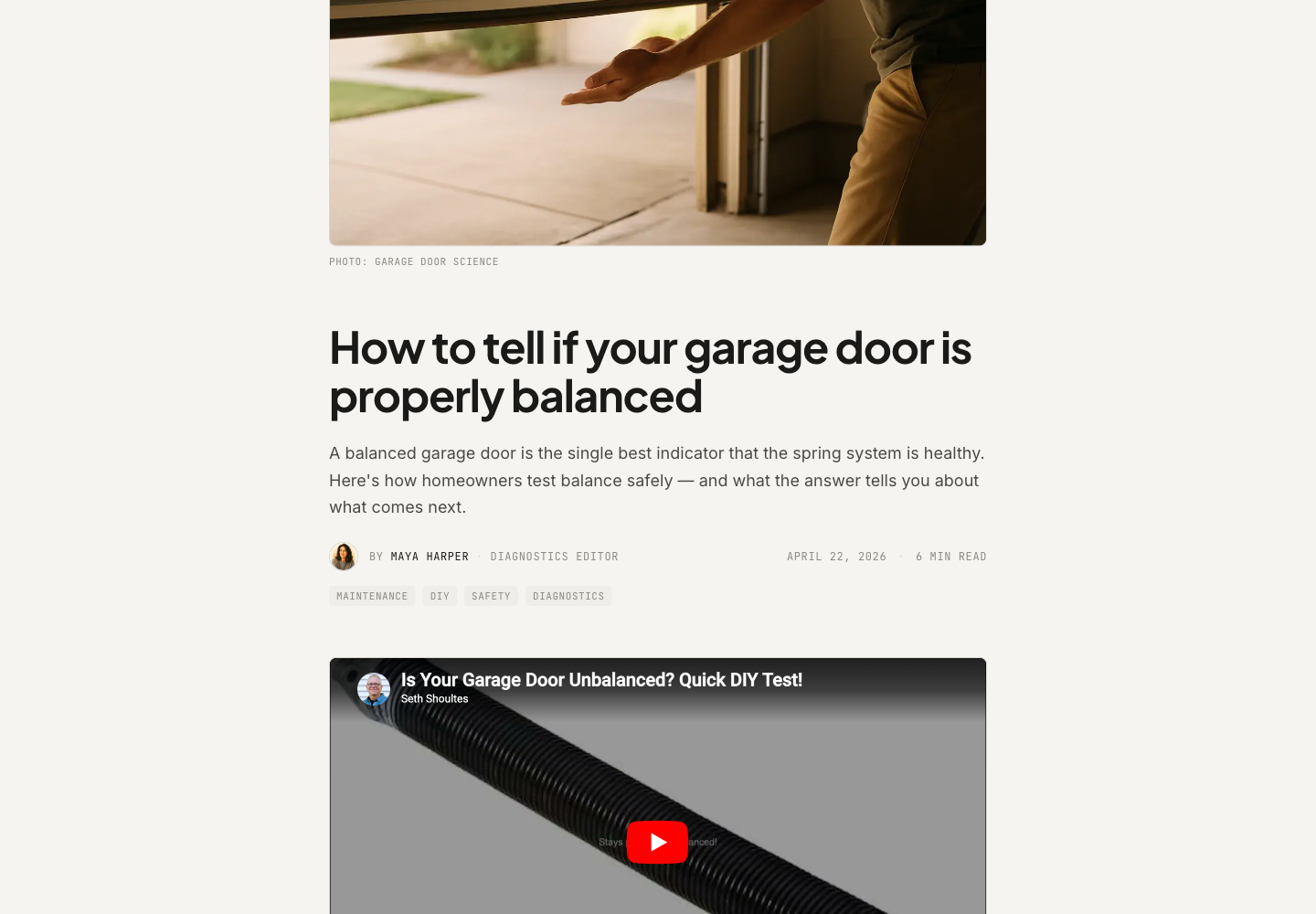
The cost of the two runs — draft, edit, fact-check, URL validation, Steve's gate — was thirty-five cents in Anthropic API fees. The week's content budget, at three articles, is about $2.50.
The thirty-five cents is not the point. The point is that the article that published is good. I read it. It's accurate. The tone is consistent with the rest of the site. The safety margins it quotes are sourced. It is the kind of article I would have spent two hours writing and probably not gotten around to.
It's good because three separate processes tried to stop it before it reached a reader. Rick tried to make it leaner. Margaret tried to find the things it couldn't prove. Steve decided whether it was worth publishing at all.
None of them are nice about it. That's exactly why you'd trust them with the work.
Seth Shoultes is the founder of garagedoorscience.com. He builds things and writes about them occasionally.